4.1. Real-Time Identification and Prediction of Bats
The first stage of the identification consists on the use of a triangular filter bank. The filter bank used in this parameterization is the same as the one used to extract the features of the t-SNE plot to study species separability (
Figure 8). The filters that comprise the filter bank are created using a linear scale, which means that all the centers are equally separated. They are triangular in shape, with equal base widths and heights, so their area is unitary. These filters start at the frequency of 38 kHz and end at 80 kHz, which are the start and end frequencies of the calls of the two bat species plus a margin. That way, the frequencies below are not taken into consideration when parameterizing the signal. This is performed to avoid irrelevant noise interference in our analysis. The length of the samples to parameterize has been studied, according to the accuracy of the results obtained in training and testing the classifier. From the study undertaken, presented in
Section 4.3, we have selected the 7 ms window. An example of this kind of parameterization is shown in
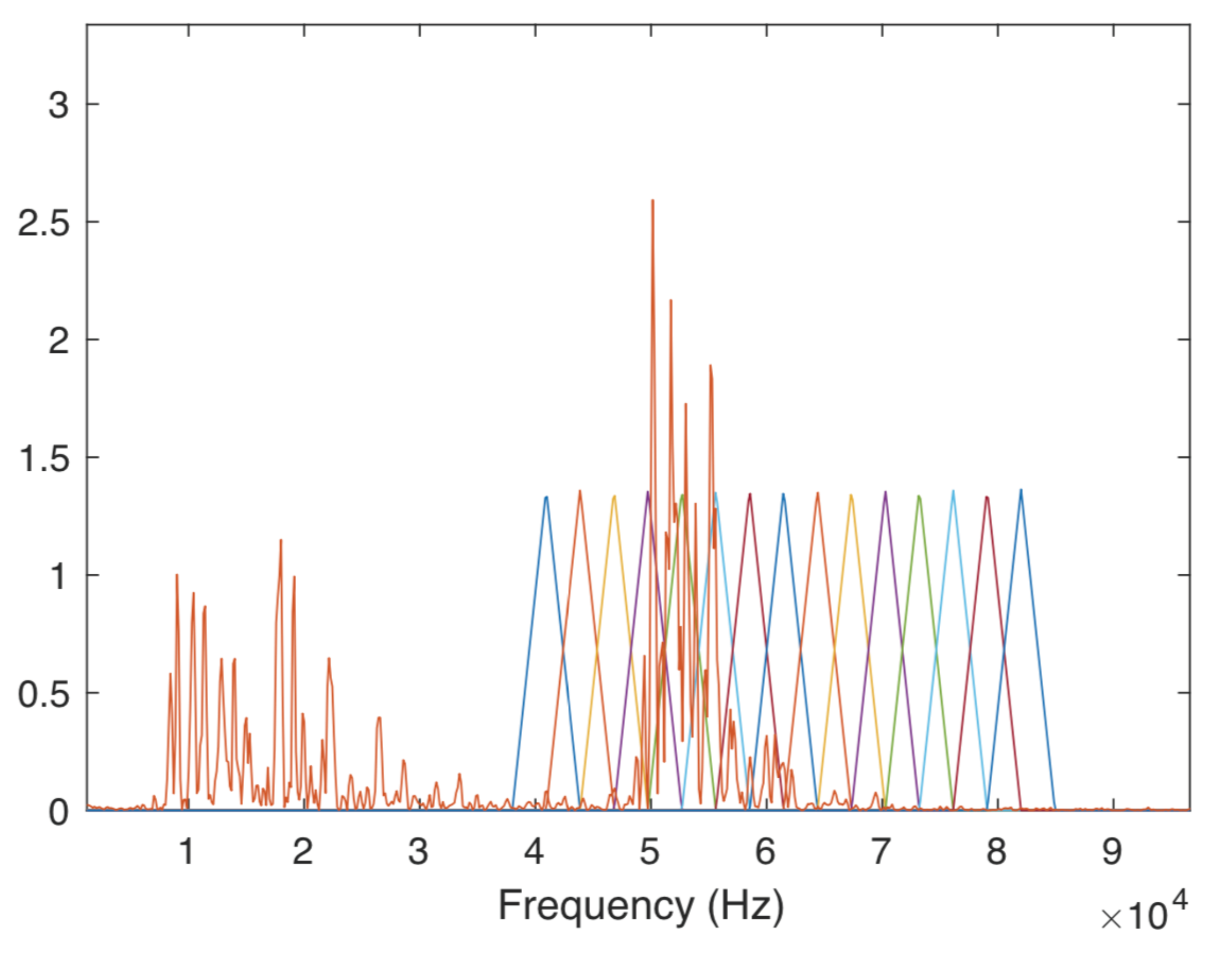
Figure 10. In this figure, a plot of the FFT of the signal and the filters that compose the filter bank are shown. The signal has energy on the frequencies of interest, but also on the lower frequencies. The methodology used only takes into account the higher frequencies.
Both the call pulses and the ambient noise of the audio files are identifiable by their power value in the spectrogram matrices, which reveals the energy of the calls at each time interval and frequency value. The second parameterization technique has followed an image processing approach, using the spectrogram matrices obtained from the analysis of the call fragments starting from 38 kHz frequency and ending at 90 kHz. Their values have been normalized. The Y axis of the matrices corresponds to frequency and its X corresponds to time. As all the sizes are equal, the temporal length used has also been studied to achieve the best performance in the machine learning algorithms. In this case, we have used 20 ms length matrices, after the study described in
Section 4.3. An example of a 400 ms length audio file parameterization is shown in
Figure 11.
The example of
Figure 11, which has five call intervals, has generated four matrices. The fact that one matrix has not been generated is because the distance between the last call and its predecessor was not enough to create two separated matrices that contain only a call. This last call is encircled in purple colour. Both calls would have appeared in the same matrix, so the specifications of the model we wanted to create would have not been accomplished. The last call is discarded and it is not used to train the model.
4.2. Design of the Neural Network Algorithm to Classify the Bat Calls
Several machine learning algorithms were tested for a further comparison of their results and the highest performing ones were selected. Before using the machine learning algorithms, the dataset was balanced, equalizing the number of audio fragments in each of the categories. We used both basic and complex classifiers to find the algorithms that were better adapted to the problem. The basic classifiers used were Random Forest (RF) [
50], the Gaussian Naive Bayes (GNB) [
51], and Linear Regressors (LR) [
52]. Two Neural Networks (NN) were also used: a Feedforward Neural Network (FNN) [
53] and a Convolutional Neural Network (CNN) [
54]. The performance results obtained demonstrate that simple algorithms achieve higher recall scores but worse precision scores. In the case studied, our concern was to ensure that the prediction outputs were correct, so the metric that we were most interested in were precision or specificity. For that reason, the Neural Networks were chosen as the algorithm to use.
We have used the two different Neural Networks (NNs) that best fit each parameterization of the data. For the filter bank coefficients parameterization, a simple FeedForward Neural Network (FNN) has been used [
53]. This kind of network has been elected both for its simplicity and for its good performance with speech recognition [
55]. For the energy matrices parameterization, the network used has been a Convolutional Neural Network (CNN). The use of the spectrogram energy matrices gives an image processing approach to the problem and this kind of network achieves high accuracy results in automatic image classification [
56].
The models have three categories of data to predict, as they have been trained with the three classes: Pipistrellus pipistrellus, Pipistrellus pygmaeus, and silence. In this stage, in the machine learning algorithms design, the train and validation takes into account three categories, there is no previous selection of bat call against silence, despite the design of the dataset has used this kind of algorithms. The FNN is composed of three dense layers, which define a fully connect each input to each output within its layer. They have a relu activation defined, which transforms any negative input given to zero. It is composed of a first hidden layer with 14 nodes, a second hidden layer with seven nodes, and a final output layer used for regression. The last layer is activated by a softmax function. In both classifiers, the dataset has been split into three categories, which correspond to the training (64%), the validation (16%) and the testing datasets (20%).
Firstly, the training set has been used to fit the model. Each time the model was trained, a test using the validation set was performed to fine-tune its parameters, such as the number of layers that composed the network or the batch size used to train the model. Performance parameters were gathered to avoid overfitting.
The final performance parameters obtained, shown in
Table 1, reflect how different the silence intervals are from the bat calls, as this category is clearly differentiated from the others. On the other hand, bat calls are more likely to be mispredicted. These results coincide with the t-SNE [
49] results of the already commented
Figure 8.
For the energy matrices, a CNN [
54,
56] is used. This kind of network is used in computer vision to analyze images and extract their most important and unique aspects that can differentiate them from others. Although our data is not originally an image, the followed analysis procedure is the same. The model is composed of two convolutional layers, whose function is to detect patterns on the matrices received as input. Those layers are configured with eight filters, which define the matrices that slide across each 3 × 3 block of values from the input matrix. We have used two layers, with the first one being responsible for capturing the low-level features and the second the one in charge of perceiving the high-level features. Between the two convolutional layers, a max pooling layer reduces the spatial size of the convolved feature. The computational power to process the data is decreased with dimensionality reduction, extracting the maximum value of each of the obtained matrices. Then, the data are converted into a vector by a flatten layer, and is propagated through a FNN. This NN is composed by two dense layers have 8 and 3 nodes respectively, and the prediction is computed using the
softmax classification technique.
Compared with the use of simple FNN, CNNs perform best on capturing local information, such as neighboring pixels in an image and reducing the complexity of the model with the reduction of the number of units in the network by the pooling layer, performing many-to-one mapping. That endows the network with a faster training, the need for fewer samples, and decreases the likelihood of overfitting. The use of a FNN is common in both cases, with the input vector in this case obtained by the flatten operation at the end of the convolutional process. As the parameterization of the data obtained from the filter banks was of the vector type, which is easier to process due to its reduced complexity, it could be directly used as input for the FNN. In this case, the training data have also been split as stated in the previous methodology, with 80% being used for its training and validation and the remaining 20% for testing purposes, using a 5-fold cross-validation principle.
Regarding the obtained performance results (
Table 2), the results of this model are higher compared to the ones obtained with the FNN. The highest performance enhancement has been on predicting silences, with an enhancement of approximately 15% in the F1 score, from 77.10% to 90.17%. The F1 score of bats [
57] has also increased by nearly 10%, achieving in this case F1 score of 74%. These results reveal that the shape of the energy of the pulses in the frequency domain is different, and its study by means of image processing gives good results.
4.3. Study of the Window Length to Use for Parameterizing the Data
For both methodologies, the temporal size of the data for its parameterization has been studied. For its study, the testing files have been split in fragments of fixed length. The studied lengths were estimated by considering the overall duration distribution of the calls. After each of these splittings, a new dataset was created and the obtained data was used to train the prediction model. The length that achieved the best results was the one that was used.
Table 3 presents the overall F1 score [
57] obtained for the filter bank coefficients method and
Table 4 for the spectrogram matrices parameterization. The data contained in the tables are plotted in
Figure 12 and
Figure 13. To obtain both results, a 5-fold cross-validation has been computed.
In
Figure 12, the F1 scores of the different window lengths are drawn. On the one hand, silent fragments do not suffer any severe variation through all the studied window lengths. On the other hand, bat calls do not achieve good prediction results when being parameterized using short window lengths. The low performance when using short frames indicates that the model can not obtain enough information from those data to make accurate predictions. Until the 7 ms window, the bigger the length of the window, the better the performance. Afterwards, results are stabilized, remaining roughly constant although the window expands. From the results obtained, we see that the model’s learning rate decreases after the 7 ms window length. For that reason, it has been decided to select the 7 ms window as the one to use.
In the case of
Figure 13, there is a performance improvement at shorter matrices and a deterioration at longer ones. The usage of short matrices does not give enough information to the network to enable it to accurately predict the specie. That could be because the full pulse is not long enough to fit into a short length matrix and just one part of it is analyzed. Contrarily, after 50 ms length, the results of the network decrease, possibly because there is more than one call present in the same matrix, and that generates errors in the estimation of the bat species. The point at which the results stabilize, 20 ms, is the one to be used, as this is the minimal length matrix from which the model can obtain the necessary information to make a reliable prediction.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}